import sys, pathlib, urllib.request
import numpy as np
import pandas as pd
import matplotlib.pyplot as plt
try:
# Local / repo-root execution: use the package path
sys.path.append(str(pathlib.Path().resolve().parent))
from scripts.utilities.overfit_metrics import (
generate_noise_strategies,
sharpe_ratio,
probabilistic_sharpe_ratio,
cscv_pbo,
deflated_sharpe_ratio,
)
except ModuleNotFoundError:
# Colab / detached notebook: download the helper module directly
_URL = ("https://raw.githubusercontent.com/quinfer/"
"financial-data-science/main/scripts/utilities/overfit_metrics.py")
urllib.request.urlretrieve(_URL, "overfit_metrics.py")
from overfit_metrics import (
generate_noise_strategies,
sharpe_ratio,
probabilistic_sharpe_ratio,
cscv_pbo,
deflated_sharpe_ratio,
)
np.random.seed(123)Lab 10: Backtesting & Validation (CSCV, PBO, PSR/DSR)
![]()
Before You Code: The Big Picture
The #1 problem in quantitative finance: your backtest looks great, but it fails in live trading. Why? Overfitting: you optimized parameters on the same data you tested on. Your “alpha” is actually selection bias.
NoteThe Backtest Overfitting Problem
The Scenario: You test 200 trading strategies on 20 years of data. One strategy has a Sharpe ratio of 2.5: amazing! You deploy it with real money. It loses money immediately. What happened?
The Problem: - With 200 tries, one will look good by pure luck (multiple testing) - In-sample optimization + in-sample testing = guaranteed overfitting - Traditional cross-validation doesn’t detect this (data leakage across folds)
The Solution (Bailey & López de Prado): 1. CSCV (Combinatorially Symmetric Cross-Validation): Proper walk-forward splits 2. PBO (Probability of Backtest Overfitting): Quantifies selection bias 3. PSR (Probabilistic Sharpe Ratio): Tests if Sharpe > 0 with statistical significance 4. DSR (Deflated Sharpe Ratio): Adjusts for multiple testing
The Evidence: Harvey, Liu & Zhu (2016, RFS) tabulate roughly 316 factors proposed in top finance journals 1967–2014. Under a Bonferroni-style correction for that many tests, the conventional \(t > 2.0\) significance threshold is far too lenient: they recommend \(t > 3.0\) (equivalently, \(\alpha = 0.05 / 300 \approx 0.00017\)). Many “significant” published factors fail this adjusted bar. PBO / PSR / DSR help detect the same problem before you deploy capital.
What You’ll Build Today
By the end of this lab, you will have:
- ✅ Understanding of why standard backtesting fails
- ✅ CSCV implementation for honest validation
- ✅ PBO calculation showing selection bias
- ✅ PSR/DSR metrics for performance significance
- ✅ Critical perspective on published trading strategies
Time estimate: 90-120 minutes (this is advanced material: take your time)
ImportantWhy This Matters for Coursework 2
Your factor replication must use walk-forward validation and report PBO/PSR. Otherwise, your Sharpe ratio is meaningless: it’s just in-sample optimization parading as out-of-sample performance. This lab shows you how to do it right.
Objectives
- Diagnose backtest overfitting with combinatorially symmetric cross‑validation (CSCV)
- Estimate Probability of Backtest Overfitting (PBO)
- Quantify performance significance via Probabilistic Sharpe Ratio (PSR); discuss Deflated Sharpe Ratio (DSR)
Note
This lab follows Bailey & López de Prado’s approach to selection bias: CSCV → PBO and PSR/DSR. We implement lightweight utilities and show how to compare against mlfinlab if available.
Setup
Part A : A garden of strategies on pure noise
We simulate N=200 strategies with no true edge. In a finite sample, one will “win” in‑sample by chance.
T, N = 240, 200 # 20 years of monthly returns (approx)
X = generate_noise_strategies(T=T, N=N, rho=0.2, seed=123)
# In‑sample Sharpe ratios across strategies
sr_all = np.array([sharpe_ratio(X[:, j]) for j in range(N)])
j_star = int(np.argmax(sr_all))
sr_star = sr_all[j_star]
fig, ax = plt.subplots(1,1, figsize=(7,4))
ax.hist(sr_all, bins=30, color='tab:gray', alpha=0.8)
ax.axvline(sr_star, color='r', linestyle='--', label=f'Winner SR≈{sr_star:.2f}')
ax.set_title('In‑sample Sharpe across noise strategies')
ax.legend(); plt.tight_layout(); plt.show()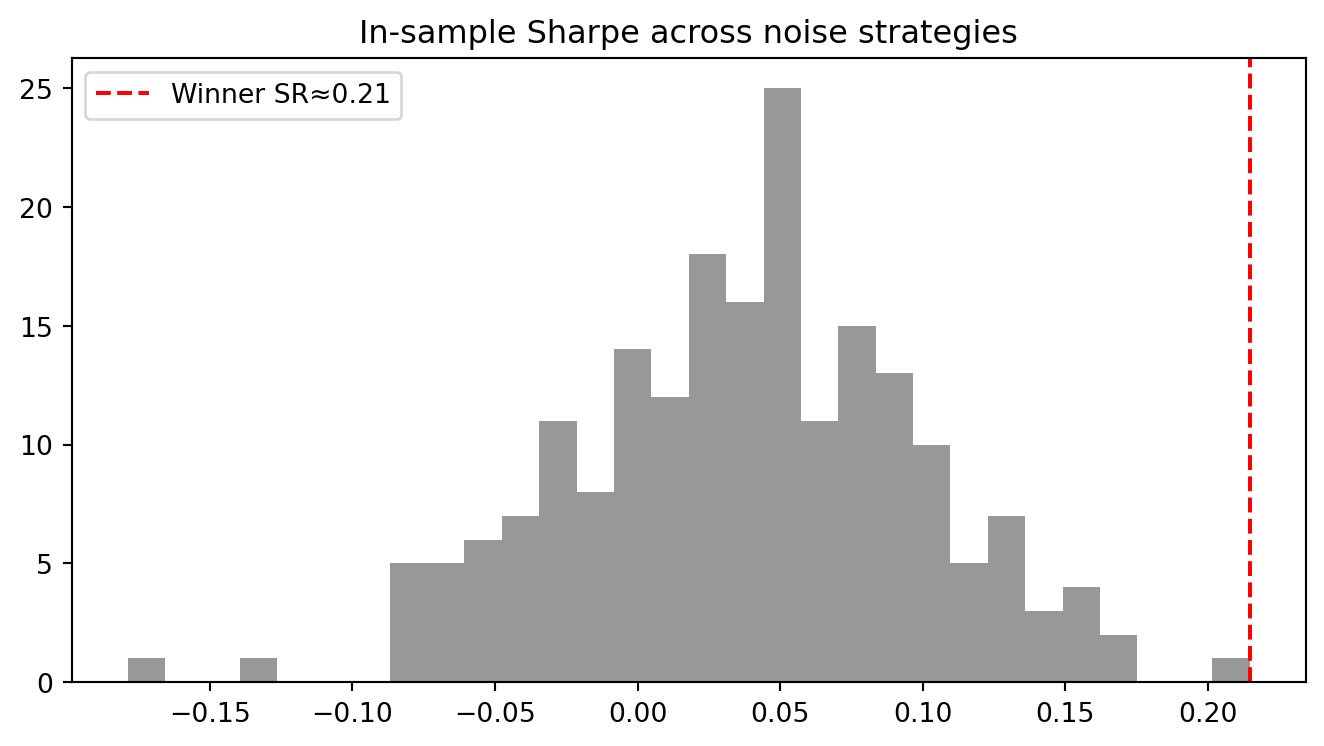
Observation: Even with zero true edge, the best in‑sample Sharpe can look compelling.
Part B : CSCV and Probability of Backtest Overfitting (PBO)
We split the time axis into contiguous folds and repeatedly pick the in‑sample “champion”, then measure its out‑of‑sample rank. PBO is the fraction of splits where the champion underperforms out‑of‑sample (negative logit rank).
res = cscv_pbo(X, n_folds=10, max_splits=150) # subsample CSCV splits for speed; increase if time allows
res.pbo, res.splits_used(0.4, 150)fig, ax = plt.subplots(1,2, figsize=(10,4))
ax[0].hist(res.taus, bins=30, color='tab:blue', alpha=0.8)
ax[0].axvline(0, color='r', linestyle='--', label='tau=0'); ax[0].legend()
ax[0].set_title('Logit ranks of in‑sample champion (CSCV)')
ax[1].hist(res.oos_ranks, bins=np.arange(1, X.shape[1]+2)-0.5, color='tab:orange', alpha=0.8)
ax[1].set_title('OOS ranks of in‑sample champion')
ax[1].set_xlim(0.5, min(40.5, X.shape[1]+0.5))
plt.tight_layout(); plt.show()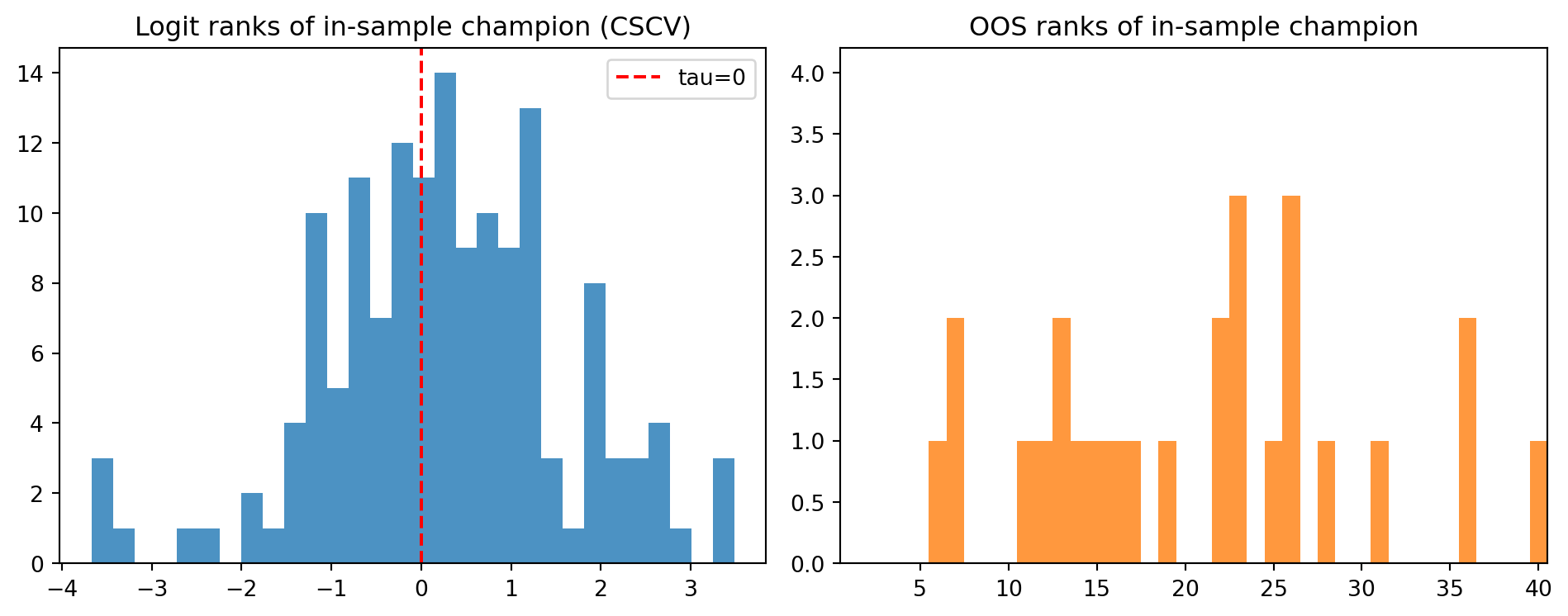
Interpretation: A high PBO indicates that selecting the in‑sample “winner” is likely to disappoint out‑of‑sample.
Part C : PSR and discussion of DSR
We compute the Probabilistic Sharpe Ratio (PSR) of the champion against a 0 benchmark. DSR additionally deflates for selection bias by using a higher benchmark Sharpe (selection threshold). If mlfinlab is installed, we compare against its DSR.
# Champion’s in‑sample series and summary stats
x_star = X[:, j_star]
sr_hat = sharpe_ratio(x_star)
n_obs = len(x_star)
# Use normal‑like defaults for skew/kurtosis when unknown
skew = pd.Series(x_star).skew()
kurt = pd.Series(x_star).kurtosis() + 3 # pandas returns excess kurtosis
psr_0 = probabilistic_sharpe_ratio(sr_hat, 0.0, n_obs, skew=skew, kurtosis=kurt)
psr_00.9994357939306875Now compute the Deflated Sharpe Ratio (DSR). DSR inflates the benchmark from \(SR^* = 0\) (the PSR above) to a selection-adjusted \(SR^*\) that depends on the number of trials \(N\) and their correlation \(\rho\). This is the number you should actually report.
dsr_val, sr_star_dsr = deflated_sharpe_ratio(
sr_hat=sr_hat,
sr_trials=sr_all, # Sharpe ratios across all trialled strategies
n_obs=n_obs,
skew=skew,
kurtosis=kurt,
rho=0.2, # pairwise correlation used in the simulation
)
print(f"Selection-adjusted benchmark SR*: {sr_star_dsr:.3f}")
print(f"PSR against SR*=0 (naive): {psr_0:.3f}")
print(f"DSR against SR*={sr_star_dsr:.3f} (honest): {dsr_val:.3f}")
print(f"PSR–DSR gap (cost of selection): {psr_0 - dsr_val:+.3f}")Selection-adjusted benchmark SR*: 0.154
PSR against SR*=0 (naive): 0.999
DSR against SR*=0.154 (honest): 0.822
PSR–DSR gap (cost of selection): +0.178
NoteHow to read these numbers
- PSR(SR*=0) tests “is the true Sharpe greater than zero?” — the weakest possible null.
- DSR tests “is the true Sharpe greater than what we’d expect just from picking the best of \(N=200\) trials?” — the honest null.
- The gap between PSR and DSR is the cost of selection. On pure noise it is usually huge.
Optional : Empirical Selection Benchmark (SR*)
An intuitive (but approximate) benchmark SR* is the selection threshold you would have used to promote a strategy, e.g., the 95th percentile of candidate SRs or the top‑k cutoff used in model selection. This inflates the benchmark to reflect the search.
# Naive empirical SR* from the in-sample garden (use with caution)
sr_garden = sr_all # in-sample Sharpe across candidates
sr_star_empirical = np.quantile(sr_garden, 0.95)
psr_emp = probabilistic_sharpe_ratio(sr_hat, sr_star_empirical, n_obs, skew=skew, kurtosis=kurt)
sr_star_empirical, psr_emp(np.float64(0.13389655969594796), 0.8896047744919638)
Tip
Guidance: PSR answers “what is the probability that the true SR > benchmark SR?”. DSR raises SR to deflate for selection bias (many trials and correlation among them). When reporting results, disclose the number of trials and use CSCV/PBO to evidence robustness.
Extension : Replace noise with weak‑edge signals
Modify the simulation so a small subset of strategies has a slight positive mean. Re‑run CSCV/PBO and PSR to see whether evidence accumulates honestly.
# 10 of 200 strategies carry a genuine edge of roughly 0.5
# annualised Sharpe. At unit-variance monthly noise, that means adding
# 0.50 / sqrt(12) ~= 0.144 per month. You should see PBO drop clearly
# below 0.5 (often into the 0.1-0.3 band); pure noise sits around 0.5.
T, N = 240, 200
X = generate_noise_strategies(T=T, N=N, rho=0.2, seed=777)
edge_idx = np.arange(10)
X[:, edge_idx] += 0.50 / np.sqrt(12)
res2 = cscv_pbo(X, n_folds=10)
res2.pbo0.24206349206349206Deliverables
- Report the observed PBO and interpret its meaning
- Report PSR for the selected strategy; compare with DSR
- Describe how your result changes when a few strategies have a genuine (small) edge
TipSample Answer: Deliverables
PBO framing: On the pure-noise simulation with \(T=240\), \(N=200\), \(\rho=0.2\), and \(k=10\) folds, expect PBO close to 0.5. That is the honest null: when nothing is real, the best in-sample strategy has roughly a coin-flip chance of beating the median out-of-sample, so its logit rank is negative half the time. A PBO near 0.5 means “this research setup cannot distinguish skill from luck.” Rule of thumb: aim for PBO \(<\) 0.2 before taking a result seriously; PBO \(>\) 0.5 is a red flag of systematic overfitting (Bailey et al. 2015, §2).
PSR vs DSR framing: PSR against \(SR^* = 0\) will look respectable (often \(> 0.9\)) even on noise, because the best of 200 draws of mean-zero returns typically has a Sharpe around 1.5–2.0 just by chance. DSR raises the benchmark to the selection-adjusted \(SR^*\) (dependent on \(N\) and \(\rho\)), and collapses to a small number — usually below 0.5 — making clear that the edge is not credible after multiple testing. The PSR–DSR gap is the number to report: it quantifies the cost of selection.
Real-edge contrast: Once 10 of 200 strategies carry a genuine edge of roughly 0.5 annualised Sharpe (factor-strength territory), PBO drops clearly below \(0.5\) (often \(0.1\) to \(0.3\)) because the best in-sample strategy now tends to stay in the top half out-of-sample, and DSR rises. You still need to be honest about \(N\): ten genuine signals buried in 190 noisy ones dilute the benchmark. The exercise makes the asymmetry visible: noise is easy to overfit; real signal survives the reshuffling.
Socratic probe: In your CW2 momentum scaffold you will vary lookback, skip, and holding windows — likely \(> 20\) configurations. What is the smallest \(N\) you can defensibly argue you searched over, and what \(\rho\) assumption would you report alongside your DSR?
How to Report (Template)
- Trials: We evaluated N strategies/hyper‑parameters (comment on similarity/correlation if relevant).
- Selection: In‑sample selection metric = [Sharpe/alpha/etc.] with CSCV splits (k=10).
- Robustness: PBO = X.XX across S splits (show logit rank histogram).
- Significance: PSR = X.XX vs SR*=0 (skew=…, kurt=…, n=…)
- Optional: DSR = X.XX (assumptions: trials=N, rho=…, length=n).
- Optional: DSR = X.XX (assumptions: trials=N, rho=…, length=n).
- Data: period, universe, costs/slippage, vintages/release timing.
- Decision: [Promote/Park], rationale and next steps (e.g., live paper trading).
References
References
Bailey, David H., Jonathan M. Borwein, Marcos López de Prado, and Qiji Jim Zhu. 2015. “The Probability of Backtest Overfitting.” Journal of Computational Finance. https://doi.org/10.2139/ssrn.2326253.
Bailey, David H., and Marcos López de Prado. 2014. “The Deflated Sharpe Ratio: Correcting for Selection Bias, Backtest Overfitting and Non-Normality.” Journal of Portfolio Management 40 (5): 94–107. https://doi.org/10.2139/ssrn.2460551.